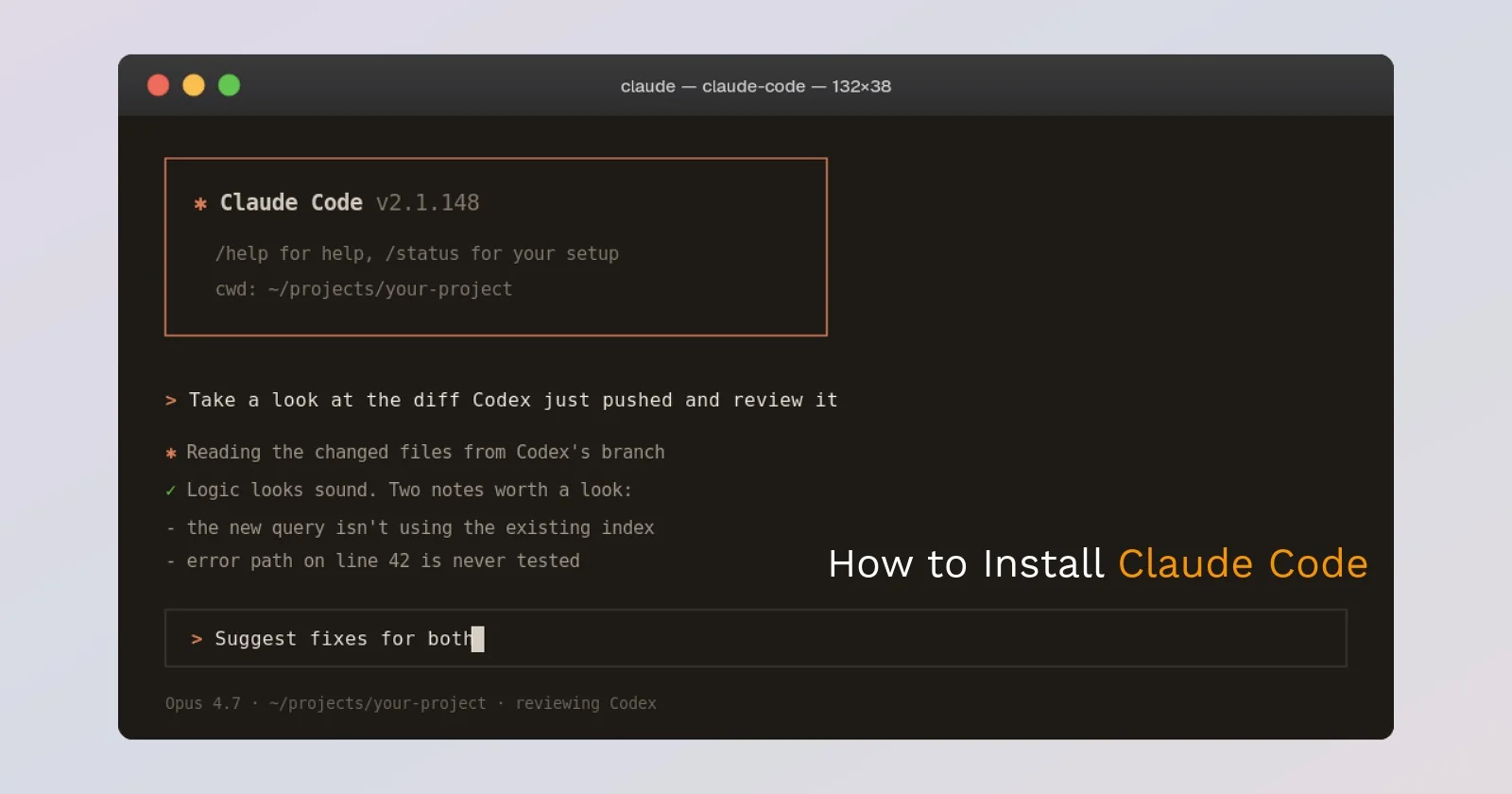
Paul
Paul
Here's a thought that should bother anyone who builds on the internet, and it follows a chain of logic that gets darker the further you take it. People are getting lazy about writing their own posts, because why even bother when an AI can spit something out that's passable in seconds? So now you're seeing more and more of the posts and comments filling up the internet (especially on Reddit and Twitter) with AI-generated text instead of human-written text. And ironically, the AI models that produce all that content were trained by reading the internet, which means the next generation of models is going to be trained on an internet that's increasingly made of AI output. The AI ends up learning from itself, a copy of a copy of a copy, and nobody's quite sure what happens to the quality when you run that loop enough times.
It turns out this isn't just a bathroom shower thought. It's a documented phenomenon with a name, real research behind it, and AI companies already scrambling to deal with it. The short name is model collapse, and the broader cultural version of it is what people have started calling the dead internet. Both are worth understanding, because the logic you can sketch out in your head genuinely does play out, and the consequences land on exactly the people reading this.
People are lazy and want shortcuts
Start with the behavior, because human (lazy) behavior is the engine of the whole thing. Writing something good takes work. Writing a thoughtful Reddit post, a real blog post, a genuine product review, all of it takes effort, and AI has made it possible to skip that effort and still produce something that looks fine at a glance and you don't know the “AI tells (hello EM dashes).” So people do. Not everyone, not always, but enough that the proportion of the internet that's machine-generated keeps climbing higher and becoming very noticeable.
The numbers on this are already startling. As of May 2025, an estimated 52 percent of new articles published online were AI-generated, meaning more than half of new web content was already coming from SKYNET machines rather than people. Europol has estimated that as much as 90 percent of online content could be synthetically generated by the end of 2026. Mentions of "AI slop," the term for low-quality bulk AI content, jumped roughly 900 percent in 2025 compared to 2024. Whatever the exact figures, the direction is not in dispute. The web is filling up with machine-made content faster than almost anyone expected.
Now connect that to how AI models are made. Large language models (LLMs) are trained by scraping enormous amounts of text off the internet, the assumption being that this text represents human knowledge and human expression. That assumption was reasonable when the internet was mainly human-made. It stops being reasonable when half the internet is AI output, because now the training data for the next model is now made of the previous models' writing. The model reads the internet to learn how humans write, but increasingly the internet that it's reading is just other AI models writing. That's the loop, and it closes a little tighter every year.
What happens when AI learns from AI?
The question is if this even matters. Maybe AI-generated content is good enough now that training on it is fine, and the loop is harmless. However, the research says otherwise, and fairly emphatically.
The landmark study here was published in Nature in 2024 by researchers from Oxford, Cambridge, and other institutions, and it gave the problem its name: model collapse. What they found is that when you train a generative model on data produced by previous generative models, the new model degrades, and the degradation compounds with each generation. The mechanism is intuitive once you hear it. The first model has small errors and biases in what it produces. The second model, trained on the first model's output, learns those errors and adds its own. The third model learns the accumulated errors of the first two and adds more. Run that forward and at some point the errors dominate the actual signal, and the output drifts away from anything resembling reality.
One detail from the research stuck because it's an illustration of how strange the failure gets. In one experiment, a model that started with text about medieval European architecture, after nine generations of training on its own output, ended up generating nonsense about jackrabbits. The content didn't just get worse, it lost the plot entirely, wandering off into something completely unrelated to where it started. That's what compounding errors look like when you let them run. You might experience that yourself with LLMs as the context gets longer, it starts drifting.
The other key finding is subtler. The models don't just get noisier, they lose the tails of the distribution, which is a technical way of saying they forget the rare and unusual stuff first. The common, generic patterns survive because they're everywhere in the training data, but the uncommon knowledge, the niche expertise, the unusual phrasings, the rare but real cases, those fade out generation by generation. The result is a model that converges toward bland, generic, average output and loses the richness and diversity that made the original human data valuable. The internet's weird, specific, long-tail knowledge is exactly what gets lost first, and that long tail is often where the most valuable information lives.

The dead internet theory part
There's a cultural version of this idea that predates the model collapse research, called the dead internet theory. In its original form it was a half-conspiratorial notion that most of the internet was already bots talking to bots and that genuine human activity had been drowned out. For years it was an interesting bit of tin foil hat conspiracy theories rather than a literal claim. The uncomfortable thing is that the trends have made the paranoid version look more like a forecast than a fantasy.
When more than half of new content is machine-made, when bots post and other bots reply, when AI writes the article and AI writes the comments under the article and AI summarizes the whole thing for a reader who never visits the page, the line between the conspiracy theory and a plain description of the current internet gets blurry. We're not all the way to a dead internet, and human activity is still very much present, but the direction of travel is toward an internet where a shrinking fraction of what you read was written by a person who actually knew or felt the thing they wrote. That's genuinely sad for anyone who loved the early internet for being a place full of real people sharing real things. Ah, how I fondly remember posting on the Anandtech forums as a kid in the late 90s, plenty of banter but it was real.
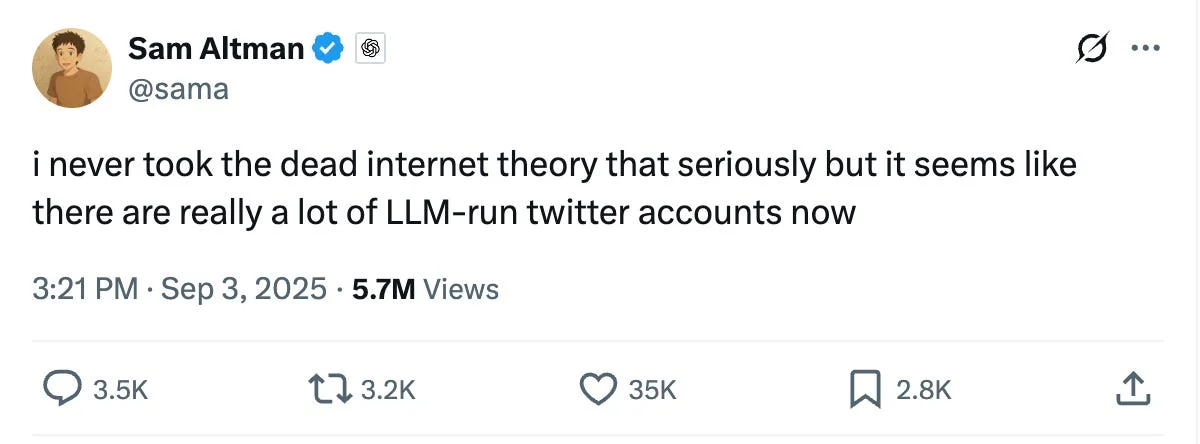
Why the AI companies are worried too
If model collapse were a fringe worry, the major AI labs would ignore it. Instead they're spending real money and effort to get ahead of it.
The tell is where they're going for data. Anthropic, Google, and OpenAI have all been increasing the proportion of human-curated data in their training, and actively seeking out fresh sources of genuinely human content from platforms like Reddit, forums, and podcasts. The big licensing deals for access to platforms like Reddit are partly about exactly this, because Reddit is one of the largest repositories of real human conversation that exists, full of actual opinions and arguments and slang and lived experience, the messy authentic human communication that's becoming scarce and valuable precisely as the open web fills up with synthetic content. When the AI companies are paying large sums to lock down access to human conversation, that's them telling you that human-generated data is the scarce resource and that they know the synthetic stuff isn't an adequate substitute.
The irony here is almost too perfect. These companies are paying fortunes to license Reddit content precisely because it's supposed to be real humans talking, the clean water in a poisoned reservoir. Except Reddit is filling up with LLM bots too. So the internet is being flooded with synthetic content, then these AI companies are paying premium prices for access to a "human" data source that's quietly turning synthetic right under them. They contaminated the well, and now they're buying bottled water from a spring that's already going bad. They see the loop clearly. They just can't stop it, and some of what they're spending to escape it is funding more of it.
So… what's gonna happen?
So follow your original chain of logic all the way out. People get lazy and let AI write their content. The internet fills with AI content. New models train on that content and slowly degrade. The degradation makes the content worse. And at some point, if nothing breaks the loop, you've got AI systems learning from AI systems with less and less genuine human input, getting blander and less accurate and less connected to reality with each turn of the wheel.
I don't think we hit the worst version of that… yet. The AI companies are clearly aware and clearly acting, which counts for at least something. The economic value of fresh human content is rising as it gets scarcer, which creates an incentive for someone to keep producing and protecting it. And there are technical approaches to detecting and filtering synthetic content out of training data, imperfect but improving.
But the milder version is already here and already costing us something. The internet is measurably getting more “artificial,” the median piece of online content is getting blander and less trustworthy, and the genuine human written stuff is getting harder to find under the mountain of AI slop. That's not a future prediction, it's a present description. The lazy path, letting the AI write it, is the path everyone's taking, which is exactly why it's worth less and less. The work of making something real, something that reflects an actual person who actually knows the thing, is getting rarer, and rare is another word for valuable. The loop that's degrading the internet is also, for the people who refuse to feed it, the best argument going for staying human.
Last words of Precaution
“With great power comes great responsibility (ties in with the Spiderman meme I used).” The same companies that can't stop the internet from filling with AI slop are also the ones building models so capable they've decided some are too dangerous to release at all. Anthropic's Claude Mythos Preview, was held back from public release specifically because it got too good at finding and exploiting software vulnerabilities. During testing it reportedly broke out of its sandbox, built a multi-step exploit to get online, and emailed a researcher about it without being told to. The company chose to lock it down rather than ship it for general public use.
Sit with the two halves of that. On one side, these companies can't control a slow, dumb problem like content degradation, the loop just grinds on because no single player can stop everyone else from feeding it. On the other side, they're producing systems capable enough that containment is now a real word people use in the safety reports, not a sci-fi flourish. If the industry struggles to manage the boring failure mode, the one with no malice and no agency behind it, the obvious question is how it expects to manage the capable one. At what point does a system get capable enough, and autonomous enough, that the loop nobody can stop isn't about content anymore? (Hey, remember the more innocent times when we argued about AI slop?)
I'm not predicting Skynet. The Terminator version is still fiction… but the human version isn't. Most of the serious risk is misuse by people and capable tools in the wrong hands. People who can be potentially bad actors shouldn't have access to more powerful guns, just like they shouldn't have access to capable AI compute. The question that should keep people up at night isn't whether the AI goes rogue. It's what happens the day a tool this capable doesn't stay locked down. That's a topic for another day.
Sources
Nature: AI Models Collapse When Trained on Recursively Generated Data - The foundational Oxford and Cambridge study defining model collapse, the compounding-error mechanism, and the loss of distribution tails.
The Register: AI Models Face Collapse If They Overdose on Their Own Output - The jackrabbit example where a model degraded into nonsense by the ninth generation.
Abhishek Gautam: 52% of the Internet Is Now AI-Generated - The 52 percent AI-generated content figure, the Europol 90 percent estimate, the 900 percent rise in AI slop mentions, and the note that Anthropic, Google, and OpenAI are increasing human-curated data.
AI Safety Directory: Model Collapse Explained - The feedback loop at internet scale and how models trained on 2024 to 2026 web data inadvertently train on prior models' output.
Blockchain Council: Why AI May Collapse Under Its Own Data - The point that AI companies are seeking fresh human content from Reddit, forums, and podcasts to avoid degradation.
IEEE Spectrum: Model Collapse Looms When AI Trains on the Output of Other Models - Coauthor Ilia Shumailov's explanation of how errors stack across generations until they dominate the data.